Ascend · Solo design + build · 2026
A nervous-system regulation app for executive-dysfunction freeze. Shipped solo to the App Store.
An AI-native app that catches the moment someone freezes and hands back one next move. Every product decision was a subtraction: five things this system is architecturally unable to do to you, each one enforced in code. Live on the App Store since June.

main, 31 Jul). Two payment stacks, three tiers, two stores, all shipped.The system
Five things it cannot do to you
A product for people who freeze under load is mostly defined by what it is not allowed to add. Every constraint below is enforced in code rather than in copy, and every one of them cost something to enforce.
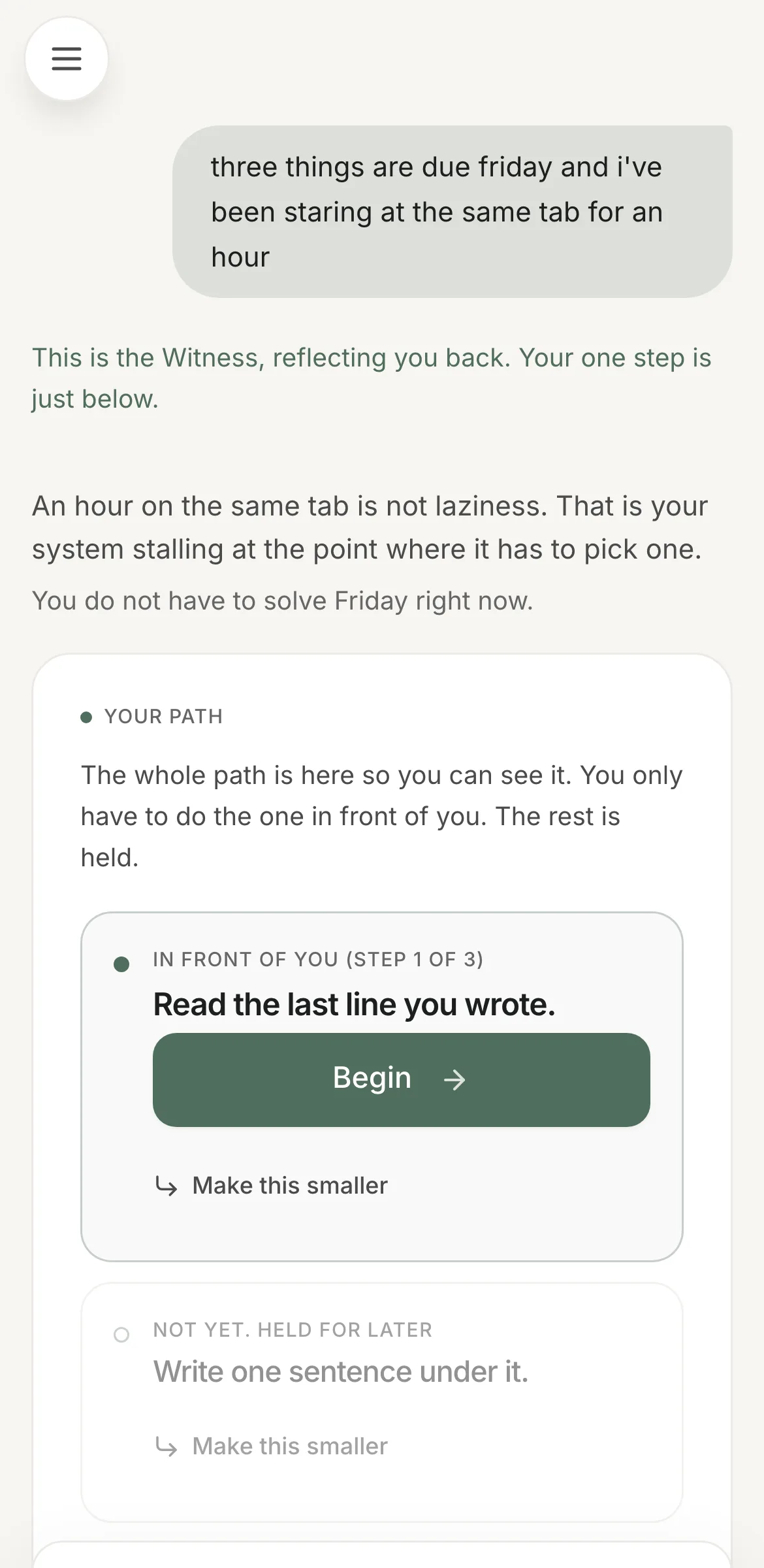
1. It cannot hand you a list
Single-action output is the core product constraint, not a UI preference. The model returns one action, with at most two refinement chips, validated against a schema that admits exactly one — it cannot answer with a paragraph.
But a schema only constrains shape, and a model will smuggle a list back in through the prose. So there is a micro-step size validator that reads the model's own output and rejects it for compound verbs, comma-separated actions, "then"-linking, numbered sub-actions, or timer framing. Two retries. And on exhaustion the turn fails honestly rather than shipping a canned step.
The alternative I rejected: a ranked list of 3–5 suggestions. Faster to build, and it reproduces the exact trigger the product exists to remove.

2. It cannot hand you a debt
The product needed a sense of accumulation and could not have a streak. Streaks are the cleanest example of the thing this app exists to interrupt: a counter that punishes a bad week is a productivity tool wearing a wellness costume.
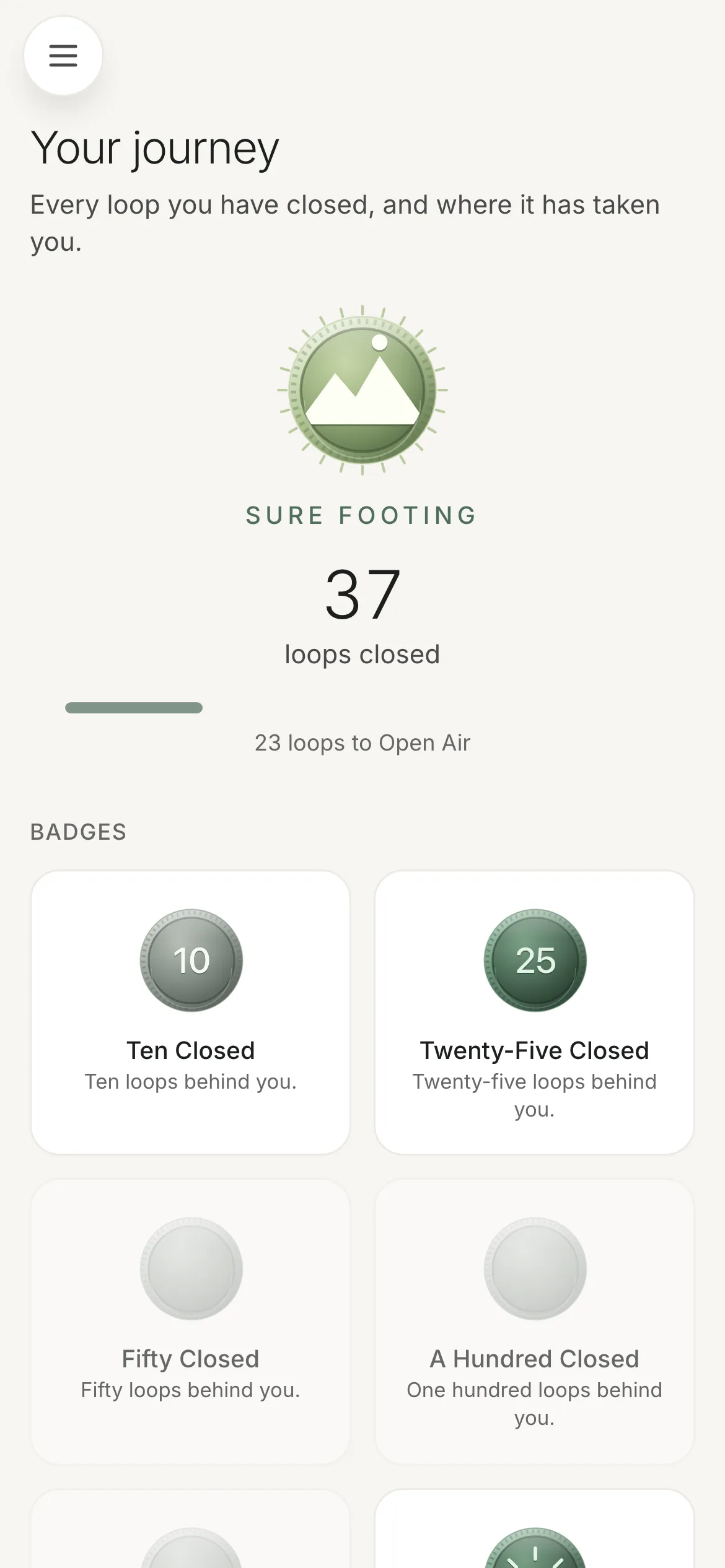
So rank is a pure function of lifetime loops closed — a number that only goes up. Ten named tiers on ascent imagery, from First Light at one loop to Long Horizon at 550, and past the last named tier the ladder generates onward every 200 forever, so a heavy user never hits a dead end that reads as "you're done." A bad week cannot take a rank away, because there is no mechanism by which it could.
Badges use the same trick for the same reason: a badge is derived from the immutable facts of a closed loop — the hour it closed, its shape, the age of what it closed — rather than awarded by a mutable counter. A loop that closed before 7am satisfies that badge forever. "Earned once, never revoked" is automatic rather than enforced.
The /journey surface shows earned and unearned together, and the guardrail moved into how rather than whether: unearned badges are struck blanks, and there is deliberately no "3 of 15 collected" counter and no padlock, because a completion tally is what turns a collection into an obligation.
The generalizable version: every gamification mechanic that creates guilt does so by being revocable. Streaks break, counters reset, badges expire. Make the state a pure function of monotonically increasing history and the guilt vector becomes structurally impossible rather than merely discouraged by copy review.
3. It cannot fake having heard you
This is an architectural rule with a line in the codebase behind it: a fallback must never impersonate the Witness. A deterministic reframe plus a catalog step, returned as a 200, is indistinguishable to the user from a real reflection — and in a product whose entire value proposition is being heard, a convincing fake is worse than a visible failure.
So when the model fails, the signed-in route returns an honest failure and the client offers a one-tap resubmit. It does not hand back a plausible-looking canned reflection. The same ruling governs the size validator: on exhaustion the turn fails rather than shipping a generic step.
I have had to enforce this twice in production against my own earlier code, which is how I know it needed to be a rule rather than a preference.
4. It cannot bill you for talking
Metering charges completed loops, not model calls. An abandoned loop costs nothing. Every refinement turn inside a loop is free. The allowance is checked once, read-only, at loop start; the charge lands at close.
And the decision I'm still proudest of survived the move to the App Store intact. If the user's scored arousal is at or above 0.7, the cap is bypassed and generation runs anyway. The user in the worst state is the user least able to handle a billing wall, and a product whose thesis is zero-guilt cannot let revenue logic override that.
There's a second rule underneath it that reads like a throwaway and isn't: the client is not allowed to say no. The local entitlement check is advisory only — telemetry — and the request fires regardless, because the client's mirror defaults to "free" and had been locking out comped accounts, webhook upgrades, subscribers on a new device, and active trials. The client is the thing most likely to be wrong, so it doesn't get a veto.
5. It cannot nag you
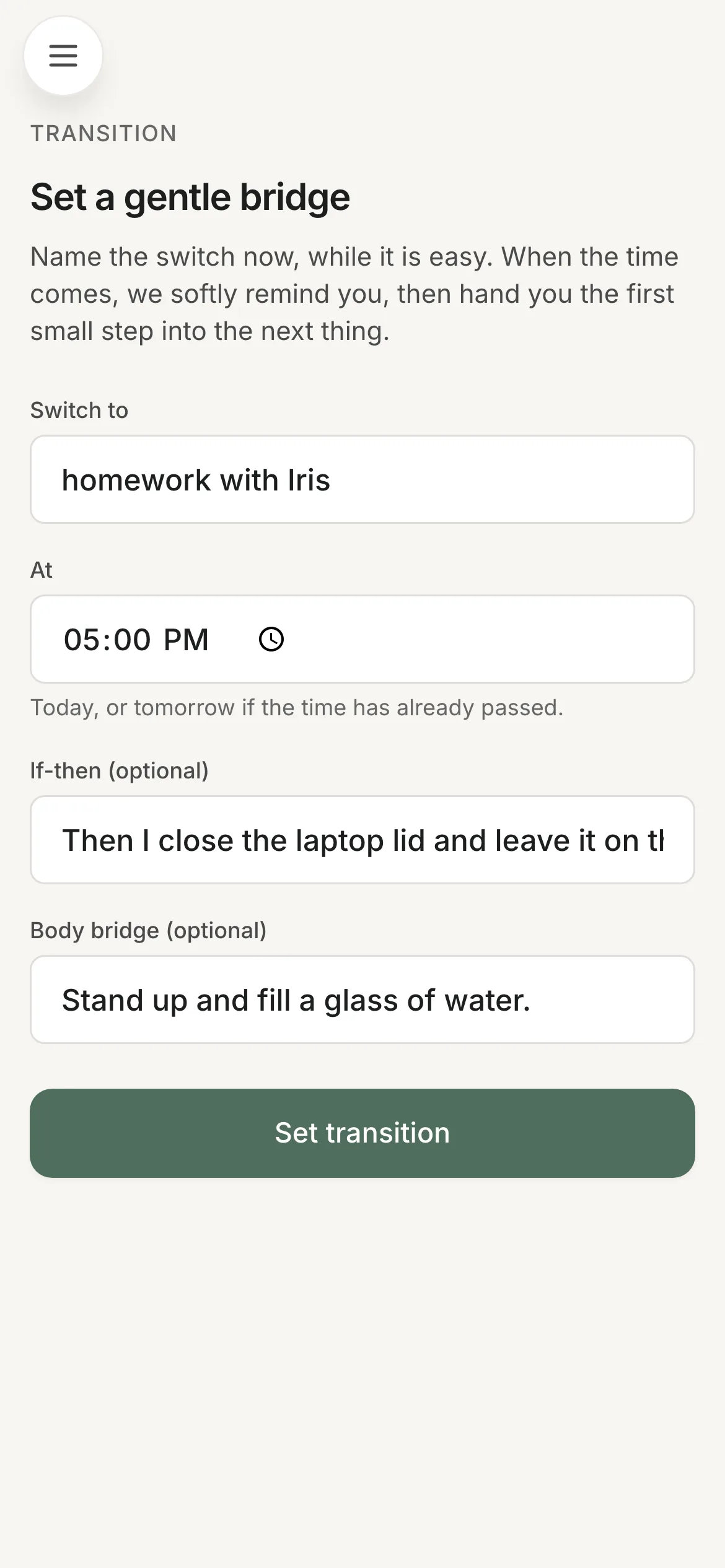
The previous version of this case study said, in bold, that I would not ship proactive push notifications — and named the condition: only when the notification could be state-aware rather than time-based nagging.
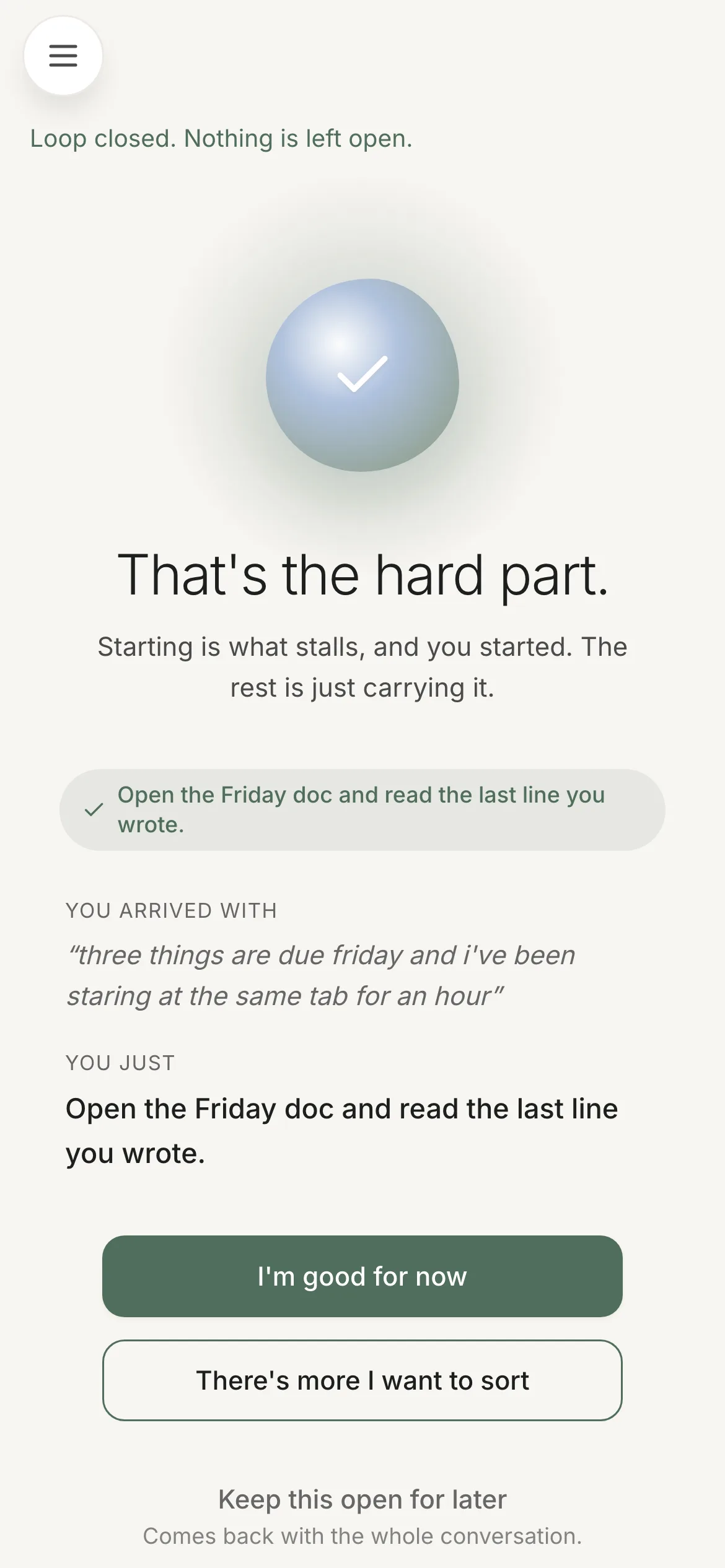
Push shipped. What I built isn't calendar-informed inference, so I want to be precise about how it clears the bar rather than claim it does. A transition cue is authored by the user: you write your own switch and its time — "move to homework with Iris at 5pm" — optionally an if-then and a physical bridge, and a cron delivers it at minute accuracy. It is time-based. But the time and the words are yours. The system never decides you need interrupting; you did, in advance, in your own words.
The delivery job earns a line of its own: it atomically claims a cue in a transaction before sending, so overlapping ticks can't double-fire, and a user with no push channel is deliberately not claimed, so the cue survives to surface in the app later.
Transferable: the adaptive-intervention pattern, progressive disclosure under cognitive load, and flat-domain organization instead of nested hierarchy. That last one is a code fact rather than a metaphor — there are exactly eight non-nested life domains, and they are used as a scoring input rather than a tree the user navigates. Two of them colliding in one sentence is itself a signal: work bleeding into family raises the arousal score directly.
The engine, and a correction
I built a deterministic router. Then I demoted it.
An earlier version of this page said the core was "a decision engine, not a chatbot" — that code picked the intervention type before the model wrote a word. That is true of the pre-signup demo and false of the signed-in product, and I'd rather tell you the real trajectory, because it's the more interesting one.
What I built
A pure, server-only router. Input text is scored into a six-dimension state vector — arousal, valence, capacity, time pressure, task clarity, and depletion — by weighted keyword matching plus text features, with no model call at all. A quadrant cascade picks a type, a modifier pass adjusts it, and a recency rule swaps the type outright if the last one was the same and the user abandoned or released it.
The best thing in that file is the depletion split, and it came from a real failure. Depletion was originally folded into arousal. Which meant "i feel numb. nothing matters." scored as activated and got routed to a breathing exercise — a regulating breath being precisely the wrong move for someone already under-aroused. Worse, without shutdown markers in the vocabulary, that input scored as valence 0 and capacity 0.925: indistinguishable from a calm baseline. The system was confidently doing the opposite of the right thing, and reporting a healthy state while it did.
What actually runs
Keyword scoring has no memory and no conversational context. It could classify an opening dump; it could not read a real user's third turn. So in the signed-in product the taxonomy stayed and the selection moved into the model.
The five types are still a closed set — Next Step, Small Habit, Breathe First, Clear Your Head, Let It Go — enforced by a schema the model cannot answer outside of. The routing rubric moved into the prompt. And the deterministic router still runs the cold-start surface every visitor sees, plus the fallback path when the model call fails.
So the honest claim is narrower and, I think, better: the output shape is a hard contract, and the output is adversarially checked after generation. The model chooses, inside a taxonomy it can't leave, and a validator downstream will fail the request rather than let it ship a list. That's a real constraint applied where it can still be verified — not a claim that a lookup table is driving a conversation.
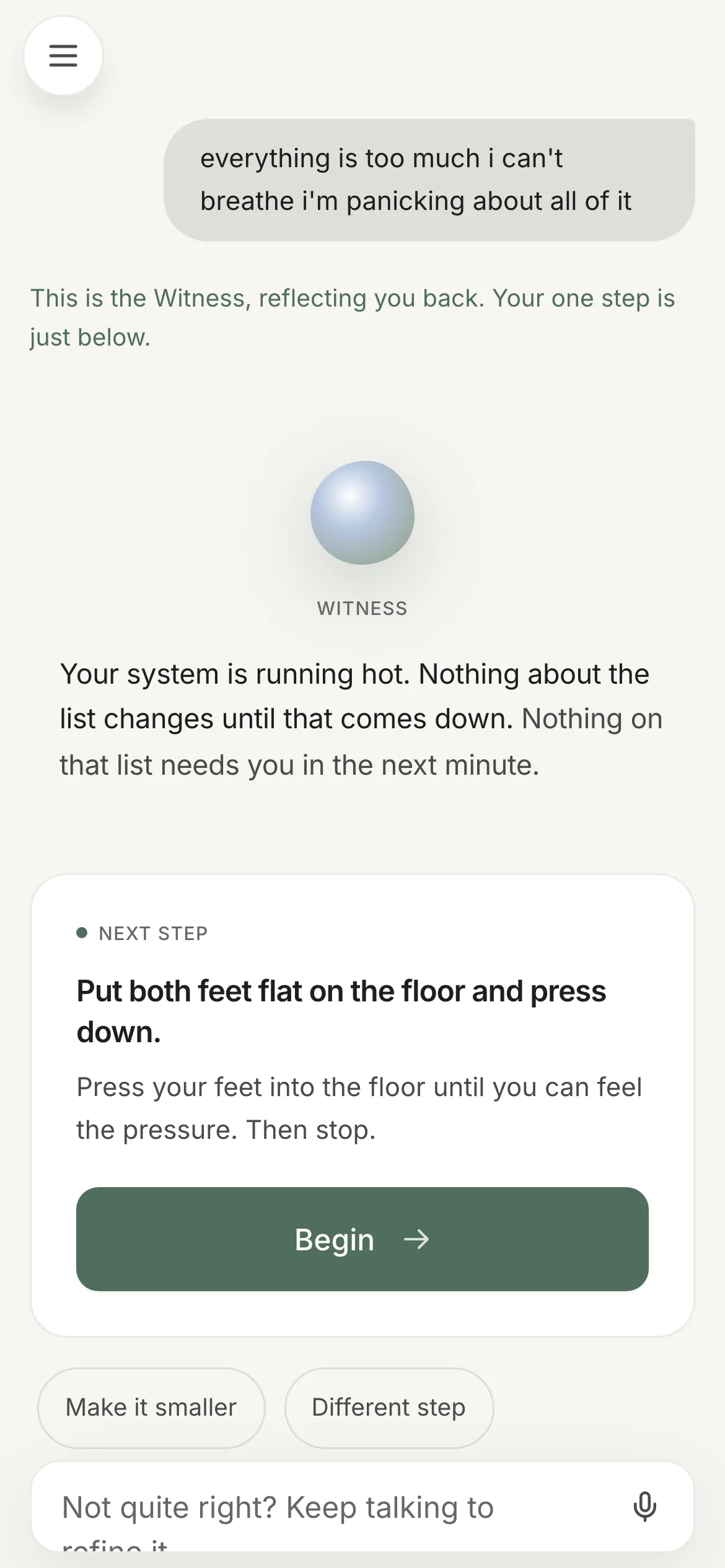
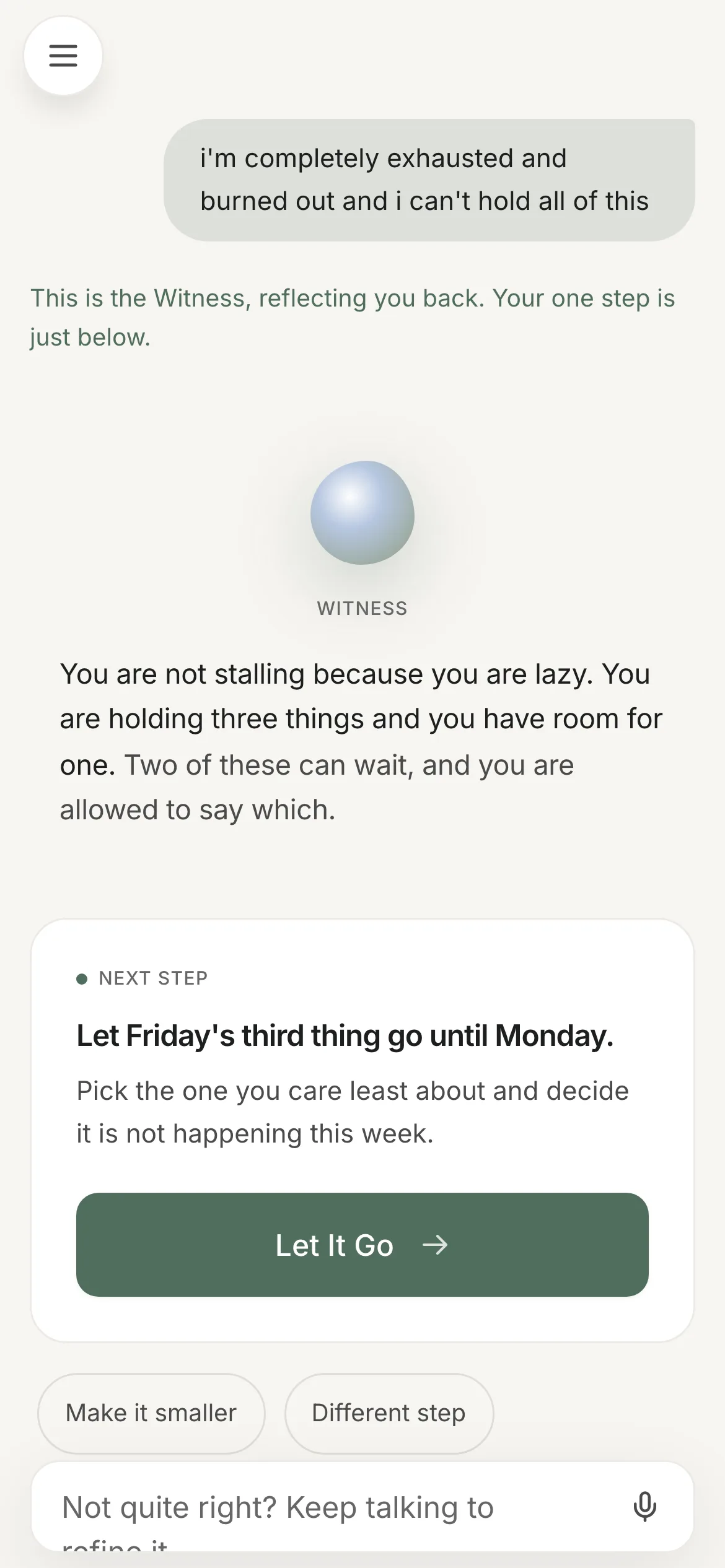
Those two shots are the routing evidence, and they make a design decision visible that I'd defend: the intervention type is deliberately not surfaced on the card. The eyebrow tells you which phase of the loop you're in, because that's what orients someone who is stuck. The taxonomy only becomes legible afterwards, on the trail. Naming the intervention type mid-loop is the app explaining itself to a person with no attention to spare.
One gap I found auditing my own product, and am not going to dress up. Of the two refinement chips, "Make it smaller" genuinely adjusts state — it speaks to the scorer through the same text channel the user has, rather than setting a hidden flag. "Different step" used to resubmit the input verbatim — it produced a different step only because the model is nondeterministic, and the pushback sentence the chip composed never reached the model at all. I found that auditing my own product and published it here as an open bug. It shipped fixed a day later: the chip now submits its own composed pushback, guarded so a too-short option cannot slip through. I am leaving the finding on the page because the audit is the point — and because I called it a two-line fix and it was not.
The problem
Lists are the trigger, not the solution
Traditional productivity tools assume the user knows where to start and just needs better organization. For people with ADHD, burnout, or high-anxiety roles, the 50-task backlog is itself the trigger. Every UI element becomes a decision point, and decision load in a dysregulated state produces shutdown, not action.
The real problem is nervous-system dysregulation triggered by cognitive overload, not task management.
Competitive gap
| Tool | Strength | Why it falls short |
|---|---|---|
| Todoist / Things | Clean task management | Lists cause paralysis, not momentum |
| Notion | Flexible, powerful | Complexity becomes its own project |
| Structured | Time-blocking | Requires knowing what to do when |
| Finch / Youper | Reflection-focused | No concrete actions |
| Goblin Tools | ADHD-friendly breakdown | No memory, no state, one-shot |
No existing tool combined witnessing — reflect, validate — with one concrete action while actively working to regulate the user's state before prescribing work.
This table is a market claim, not a code claim, and it hasn't been re-surveyed since I first wrote it. Treat it as my read of the landscape rather than as something I can cite a file for.
Voice-first input
Voice is the default input, not an accessory. When you are overwhelmed, speaking is lower-friction than writing. Transcription runs through Whisper with a text fallback. I considered keyboard-first because it ships faster; the regulation hypothesis required speaking.
An earlier version of this page claimed "about 60% of Clarity Loops begin in voice." I've cut it. There is no voice-versus-text split anywhere in the analytics schema, so that number could not have come from measurement — and a fabricated metric on a page arguing for rigor is worse than no metric. It's one field on one event to instrument properly, and until it is, I'll state the design commitment and not the number.
The system, and the words
A rule in a document is a wish. A rule wired to a gate is a constraint.
Everything on this page so far is a claim about behaviour. This section is about the machinery that stops those claims from quietly becoming false — because in a product whose entire promise is this will not do that to you, a promise that decays is worse than one never made.
Components graduate, and the door locks behind them
Anything reused across two or more surfaces graduates out of the composed-surface folder and into the primitives folder with a real variant API. The composed folder is for product surfaces — Witness, Action Mode, Trail, Pricing — and never for primitives. The tell that something is a primitive in disguise is stated plainly: if you find yourself copying a button with custom classes from one route to another, that is a primitive, and it goes in the system.
When a primitive is retired, the retirement is enforced rather than announced. The deleted import path is locked by a lint rule, so the old component cannot come back by habit. That is the same instinct as everything else here: the convention is not the thing that holds. The gate is.
Two tokens that look like one
The brand colour and the progress colour are deliberately different tokens, and the distinction is load-bearing rather than decorative. Brand is the calm register. Progress is the momentum register. A product that used one token for both would end up celebrating in the same colour it uses to reassure, which is precisely the collapse this product exists to avoid.
Constraints that read like code standards and are therapeutic decisions
No animation may reposition layout. No stagger, no entrance effects that shift adjacent elements. Minimum forty-four pixel targets. No system dialogs. Each of those is written as an engineering rule and each one prevents a specific failure for a specific user: content that moves under a person whose attention is already failing is content they have to re-find, and re-finding is where the session ends.
Content design, enforced in the same place the AI is
The product has a vocabulary with a prefer-and-avoid table and reasons attached. “Task” becomes action or step. “Productivity” becomes momentum or clarity. No wins, no streaks, no unlocks. No urgency words. No guilt vectors — nothing overdue, nothing missed, nothing broken. No exclamation marks in product copy.
The rule I would point at is the one about time. The product may never state how long a loop takes. No eight minutes, no five-minute window, no sixty seconds of clarity, no timers. Describe the loop by what happens in it, never by how long it lasts — because a duration is a performance target, and handing a performance target to someone who is already frozen is the whole failure mode in one sentence. The copy was swept across the codebase to enforce it.
And the fine line that survives the ban: naming the user’s own elapsed drift — “forty minutes on TikTok” — stays, because that is a true observation about them rather than a standard set for them.
The failure that made it one validator instead of two
The rule that a step must be smaller than feels natural started as a prompt instruction. A prompt instruction is a request, so it became a validator that rejects compound steps on four grammatical patterns, with a false-positive guard that only treats a comma as a separator when what follows is verb-led, and one named carve-out for a regulation primer leading the move.
Then the related rule — no countdowns, no timer framing — turned out to be enforced on the AI path only. The deterministic fallback catalogue was serving real users the exact string the prompt quoted as banned. A content rule enforced on the happy path is enforced where it matters least: the fallback is what a user sees when things go wrong, which is exactly when a product about regulation has to sound like itself.
So the regression test now runs every shipped intervention, every generated action, and every fallback reflection through the same validator the AI path uses. The file header ends with the rule that keeps it that way:
There is exactly one timer-framing rule in the codebase. Do not write a second one.
And the gate that keeps two platforms from becoming two products
The native port could have forked the design system quietly — that is the normal outcome, and it usually takes about two releases. Instead a gate resolves every colour token in both light and dark, follows alias chains, and asserts the ported theme carries the same value. Any token added to the web theme that is neither mapped nor explicitly skipped fails native continuous integration.
The part that makes it a design argument rather than an engineering one is that it refuses the cheaper byte-equality mechanism the other ported modules use, and says why: forcing it would mean declaring the whole file as one edit, which asserts nothing. It was proven by injecting four deliberate breaks and checking that four distinct failures came back.
This is the thing I would want judged on in five years rather than five weeks. It is not what the product does on launch day. It is what happens on day four hundred, when the interesting work is finished and the only remaining job is stopping the system from rotting.
Failure modes
What happens when the model is wrong — and when nothing looks wrong at all
| Failure | What the system does | Why |
|---|---|---|
| The model is slow | A narrated indicator advances on a real schedule — 0s "Reading what you put down", 5s "Finding the real wall in it", 12s "Sizing one step, smaller than feels natural", 25s "Still here. This one is taking longer", 45s "Making sure the step is actually small." | The phases are honest rather than theatre: the long tail genuinely is the pipeline re-checking the model's answer. The sequence holds on the last line and never loops, because looping reads as fake. |
| The step is too big | "Make it smaller" appends stuck language to the original input, which the scorer reads down into lower capacity | Lets the user nudge the engine without surfacing the model |
| Free allowance reached | Two completed loops per day, reset daily. The reflection still renders; only the next loop is refused | Being witnessed shouldn't be the thing you run out of |
| The user is dysregulated at the cap | Arousal ≥ 0.7 suppresses the limit and generation runs anyway | A user mid-spiral needs the loop more, not less |
| The model fails outright | An honest error with one-tap resubmit. Never a canned reflection | A convincing fake is worse than a visible failure |
| Connection drops mid-loop | The failed turn is trimmed from history so a resubmit can't duplicate it, the input survives verbatim, and an auto-resubmit is armed for reconnect | Losing what you just typed, in this state, ends the session |
The compliance clamp, and the collision I didn't plan
The native shells are WebViews loading the same production web app that sells subscriptions. App Store Guideline 3.1.1 says the store build must unlock no paid content and show no pricing — so the suppression has to happen inside the codebase that does the selling.
It's one token in the user agent, read server-side, which is the load-bearing choice: the server clamps the native shell's tier to free before rendering, so there's no flash of pricing that a client-side check then hides.
What it cost is the honest part. A compliance clamp is trivial to add and genuinely hard to un-add. When in-app purchase went live, the un-clamp had to be propagated to every surface that had learned to distrust the native shell — and it wasn't. One screen clamped every native session to free unconditionally, so a Pro user hit a free-tier wall on their own phone and couldn't get past it. The same defect shape turned up on a second surface, found separately. Both hit entitled users.
And the collision: the clamp operates on tier, the compassionate bypass operates on the allowance check. They never touch. Which means that inside the shipped iOS app, every user is clamped to free, so every user is on two loops a day, and the bypass is the only thing standing between a dysregulated user and a wall they cannot pay past even if they want to. A decision I made for ethical reasons turned out to be load-bearing in a build I designed it before.
What happens to someone in crisis
A person in crisis can type into this, so the disclaimer isn't sufficient on its own. There is a mandatory two-stage screen on every Witness call, on both the public demo and the signed-in loop.
The first runs before the model request is constructed and before metering — so a crisis turn never costs the user any of their allowance — and on a match it skips the model entirely and returns the 988 Suicide and Crisis Lifeline, Crisis Text Line, 911 for immediate danger, and an international directory. The second reads the accumulated turns of the whole thread rather than the current one, because the signal pair can land turns apart, and it triggers only on the pair, deliberately, so a single ambiguous phrase doesn't eject someone from a loop they're using well.
Telemetry on both is meta-only by policy: a pattern kind and a count. Never the user's text, never the matched phrase.
The limits, stated plainly: it is keyword matching, not classification, so it will miss indirect or metaphorical expression and anything not in English. The resources are US and Canada only, with one international directory link. There is no human escalation and no follow-up. It is a floor, not a safety net, and I would not put this in front of someone in active crisis as a substitute for anything.
What is not handled
Stated plainly, because a failure-modes section that admits nothing has told you nothing:
- No bot protection anywhere. The public demo is an unauthenticated endpoint calling a paid model, defended by an IP-keyed rate limit that distribution defeats trivially. It is the sharpest unmitigated risk in the product.
- No spend ceiling. Cost is logged and displayed; nothing stops. Combined with the above, an abuse event is something I'd discover on a dashboard afterwards.
- Whisper failing outright has no designed path. It falls through generic error handling. The "text fallback" is really "the text input was always there."
- Tone is unguarded. The validator checks shape, not content. A calm, well-formed, wrong-hearted reply passes every gate I have.
- Push has never been proven end to end. One registered device, no confirmed real-phone delivery.
- Android and desktop are built and unreleased. The desktop artifact on disk is about thirty versions stale. Android is waiting on the native port rather than getting a Capacitor release it would only have to replace.
The instructive bug
Silence and health look identical from inside the request path
The learning layer — reflection after a session closes, promoted into durable memory, read back into later prompts — had stopped learning entirely. For a day.
There was no symptom. Every request returned 200. Nothing errored. I looked at the surface, thought it "seemed weak," and read my own production data to find that the pipeline had written nothing since the previous deploy.
Two of the four defects are worth the space:
A token budget sized for the old model. A prior change routed reflection onto a different model but left the output cap where it was. The new model needed about 65 more tokens for the same contract — so every reflection hit the ceiling, truncated mid-JSON, failed to parse, and wrote an empty document flagged as failed.
A sort key that didn't exist on half the documents. The reader ordered by one timestamp field; mid-step turns carry a different one. Firestore silently excludes documents missing the ordered field. There is no exception. The query succeeds and returns fewer rows. So reflection only ever saw the opening dump and the first reframe — never the part of the conversation where the user says what actually blocked them, which is the only part worth learning from. The system was confidently learning from a truncated view of every conversation.
No try/catch would have helped with either. The first was caught, and logged, and flagged — and the route returns 200 by design because the client is fire-and-forget, so the failure had nowhere to go. The second was never an error at all.
Breadcrumbs only attach to a later captured error, so a wholly dead subsystem produced no signal at all. Per-event alerting closes half the hole. It cannot see the other half — a route that stops being called — because silence and health look identical from inside the request path.
The fix that mattered wasn't the token budget. It was a scheduled watchdog that compares "loops that closed" against "reflections that landed" — an out-of-band check on an expected invariant, because that is the only thing that can tell a dead subsystem from a healthy one. That generalizes to every async worker, webhook consumer, and background job anyone reading this has shipped.
The same shape, in the billing path
Users were being charged more than once for a single Clarity Loop. On the free tier — two a day — that means being cut off mid-conversation for continuing to talk: the product punishing the exact behaviour it exists to encourage.
The charge deduplicated on a session id the client minted, and the client re-minted one mid-loop. I found it by reading my own production record rather than from a report: four sessions created inside six minutes carrying byte-identical input, three of them with zero turns, and all four wrote a charge. The measured rate was 40% — twelve real loops, twenty charges, over a week.
The fix added a second dedup dimension the server owns: a content hash that suppresses a repeat charge for the same normalized input inside a window, read in the same transaction, fail-open.
The bigger half is that the dashboard which should have caught this was wrong in the same direction — it counted charge records as completed loops, overstating engagement by roughly a third while I made decisions off it. And it was dead: two indexes declared in the repo had never actually been deployed, so the page was throwing and rendering "could not load behavior data." Nobody could see the inflated number, because the surface that displayed it was erroring out.
Three lessons, and I'd take all three anywhere:
- An idempotency key you don't control isn't one. Deduplicate on something the server owns.
- A metric that counts a proxy will drift from the thing. Charges are not loops. Instrument the distinction and put the drift rate on the dashboard.
- "Unavailable" and "zero" must never render the same. A dashboard that fails to a plausible number is worse than one that fails visibly.
One more, for the ledger. The in-app purchase paywall hung forever on "Loading plans" — real users, real store build, nothing to buy. Two of my fixes chased the module import; the import was always fine. The purchases object is a proxy that answers any property read with a bridge call, which makes it look thenable — so returning it from an async function made the runtime read .then, dispatch a call to a native method named "then," and wait forever for an answer that never came. No error, no rejection, no timeout: a promise that simply never settles. await is not free on a value you did not construct. There is one regression test standing guard over that line now.
Reflection
What worked, what I'd do differently, when this approach is wrong
What worked
- The thesis drove the non-obvious calls. One action at a time, voice-first, and zero-guilt were constraints derived from the executive-function literature and my own freeze patterns, not features added afterwards. Each one is now enforced somewhere a future me can't quietly undo it.
- AI as thinking partner, not just executor. Claude Code helped me work through the recency algorithm and the Firestore index design. It did not save me from deploying a schema whose indexes I never actually shipped — see above.
- Constraints forced focus. Solo, nights and weekends, no funding. That's why the product has five intervention types and not fifteen.
What I'd do differently
- Build the ability to charge later than you think. This was already the regret on the last version of this page, and it compounded: I built Stripe before validating willingness to pay, then had to build a second payment stack for iOS because the App Store requires in-app purchase, then took four subscription products through review. That's two complete payment integrations standing ready in a product that is still in beta and has only just started marketing. None of that work was wrong — all of it was early, and the ordering is the thing I'd change.
- Having analytics is not the same as having correct analytics. I added instrumentation after the MVP, which I knew was late. What I didn't expect was that the instrumentation would then lie by a third while I read decisions off it, on a page that was itself throwing in production.
- "Shipped" is not "distributed." I used to say I'd conflated production-ready with beta-ready. That resolved itself by escalation — I skipped the closed beta and shipped publicly. Then the same error repeated one level up. Being on the App Store is not being findable on it. That's the version of the mistake I'd actually warn someone about.
- The path where money changes hands has the least test coverage. 430 test files, and the purchase-to-entitlement chain has almost none — the only store-specific test is a regression written after the paywall hang shipped. Both billing incidents were found by a human using the app. Store-mediated flows are genuinely hard to cover, which is exactly why they stayed uncovered, which is exactly why they broke.
The "this didn't land" affordance I predicted as my next UX bet on the last version of this page did ship: "Actually, I'm not done with that one" on the finish screen, which restores the path to its state before the advance and renders at the lowest visual weight on the screen. The rung stays yours to finish. No shame framing — that constraint is written into the commit.
What's being built now: the native port, and a gate that forbids it forking
The shipped iOS app is a Capacitor shell around the production web app. That's why the App Store pricing suppression had to happen server-side by user agent — the store build and the website are literally the same code. It works, and it's why the app could ship at all. It also means the phone experience is a website in a jacket.
So there's a real native app in progress now — Expo and React Native, its own bundle identifier, first testable build committed. The loop, the execute surface, and sign-in are running natively.
The interesting part isn't the port, it's the rule I wrote for it: port, do not fork. The domain logic — ranks, badges, tiers, interventions, the state vector, session shape — has to behave identically on both platforms, and copies rot silently. So there's a drift gate in CI. For every ported module it takes the web original, applies the exact list of edits the port has declared, and requires the result to match the native file character for character.
Every declared edit needs a stated reason naming the platform dependency it extracts. The script says why in its own header:
Adding an entry is a deliberate act. An entry with no such reason is a fork, and a fork is the thing this gate exists to prevent.
If it fails, exactly one of two things is true: someone changed the web file and didn't carry it across, or someone changed the native file and didn't carry it back. Both are caught the same day rather than discovered six months later when a rank threshold quietly differs between platforms and a user loses a badge by switching device.
This is the same lesson as everything else on this page, pointed at a different problem: a rule stated in a document is a wish, and a rule wired to a gate is a constraint. I've watched prose-only conventions drift into the thousands elsewhere. This one can't.
What I turned off
Retrieval-augmented memory is built, evaluated, and deliberately disabled: the ablation found no benefit, and it made the micro-step bigger, which is the one thing this product must never do. A shipped-then-disabled feature with a measured reason is a better artifact than a shipped one with no measurement.
When I wouldn't ship this approach
The adaptive-intervention pattern works when user state is inferable from a short input and the cost of a wrong intervention is recoverable within the same session. I wouldn't apply it to a tool used during an active crisis. Ascend assumes a five-to-ten minute window and a recoverable session; crisis support needs different patterns, escalation paths, and human handoff. The pattern is for coaching, not adjudication — and the screening described above is a floor under that boundary, not a crossing of it.
Status
On Ascend
Ascend is portfolio work and a real, shipped product. Publicly downloadable on the App Store since 21 June 2026, currently version 1.1.1, with four subscription products through review, a web app at justascend.app, and native shells for iOS and Android plus a desktop build.
It's a beta, and it's still being finished. The build is well ahead of the go-to-market — subscriptions are live and approved, but marketing has only just started, so the willingness-to-pay question hasn't really been asked yet. That's the honest state of it, and it's the part I'm working on now.
What the early usage has been good for is finding things. Instrumentation caught a billing defect that was double-charging at a 40% rate — in a sample small enough to count by hand. A product you can debug at that resolution is worth more right now than a bigger number would be, and it's the reason I trust the rest of what's on this page.
The thesis has a cost and I'd rather name it than let a reader find it. I built a product that cannot nag you, cannot shame you, cannot hand you a list, cannot fake having heard you, and cannot charge you for talking to it. Every one of those is enforced in code and I can show you the line. None of them was the hard part. The hard part is that a product with no obligations also has no hooks — and I chose that on purpose.
One measurement caveat, since this page argues for rigour. Every craft decision described here was triggered by me using my own product. There has been no user testing. The repo says so about itself in three places and the page should say it once: n=1. The instrumentation has caught real defects at that scale, which is worth something, but it is not research and I am not going to call it research.
What this one proves
That I can find the model under a problem that everyone else treats as a feature gap. Task managers were not failing these users because they lacked features; they were failing because the model was wrong — the load was never organisation, it was regulation. And the correction did not stop at the thesis. It kept going, one level finer, when hiding the path turned out to create its own freeze: seeing and doing are two different loads, and the product had been collapsing them into one.
I maintain it on my own time and in small windows. I'm available for full-time senior, staff, or lead IC work. Ascend does not compete with that.